


MUELLER REPORT VOL. II
Von:
Pia-Maria Michnik
Betreut durch:Prof. Kristian Wolf, JProf. Dr. Christoph Rodatz
Eine interaktive Datenvisualisierung auf der Grundlage einer systematischen Analyse der Textstruktur
Der Mueller Report, der im Originaltitel ‚Report On The Investigation Into Russian Interference In The 2016 Presidential Election‘ heißt, wurde vom Special Counsel Robert S. Mueller am 22. März 2019 in Washington, D.C. an Generalstaatsanwalt William Barr übermittelt. Der gesamte Report besteht aus zwei Teilen. In der hier dargestellten Arbeit wird technisch sowie inhaltlich nur der zweite Teil (Volume II of II) bearbeitet. Der Report befasst sich mit verschiedenen Ermittlungsansätzen und Bewertungen der Beweise, ob Donald Trump im Zuge der Präsidentschaftswahlen 2016 die Justiz behindert hat und inwieweit dabei eine Einmischung Russlands in verschiedene politische Geschehnisse erfolgt ist. Dabei bezieht Mueller mehrere zeitversetzte Ereignisse mit ein, die weitestgehend dazu beigetragen haben oder dadurch beeinflusst wurden.
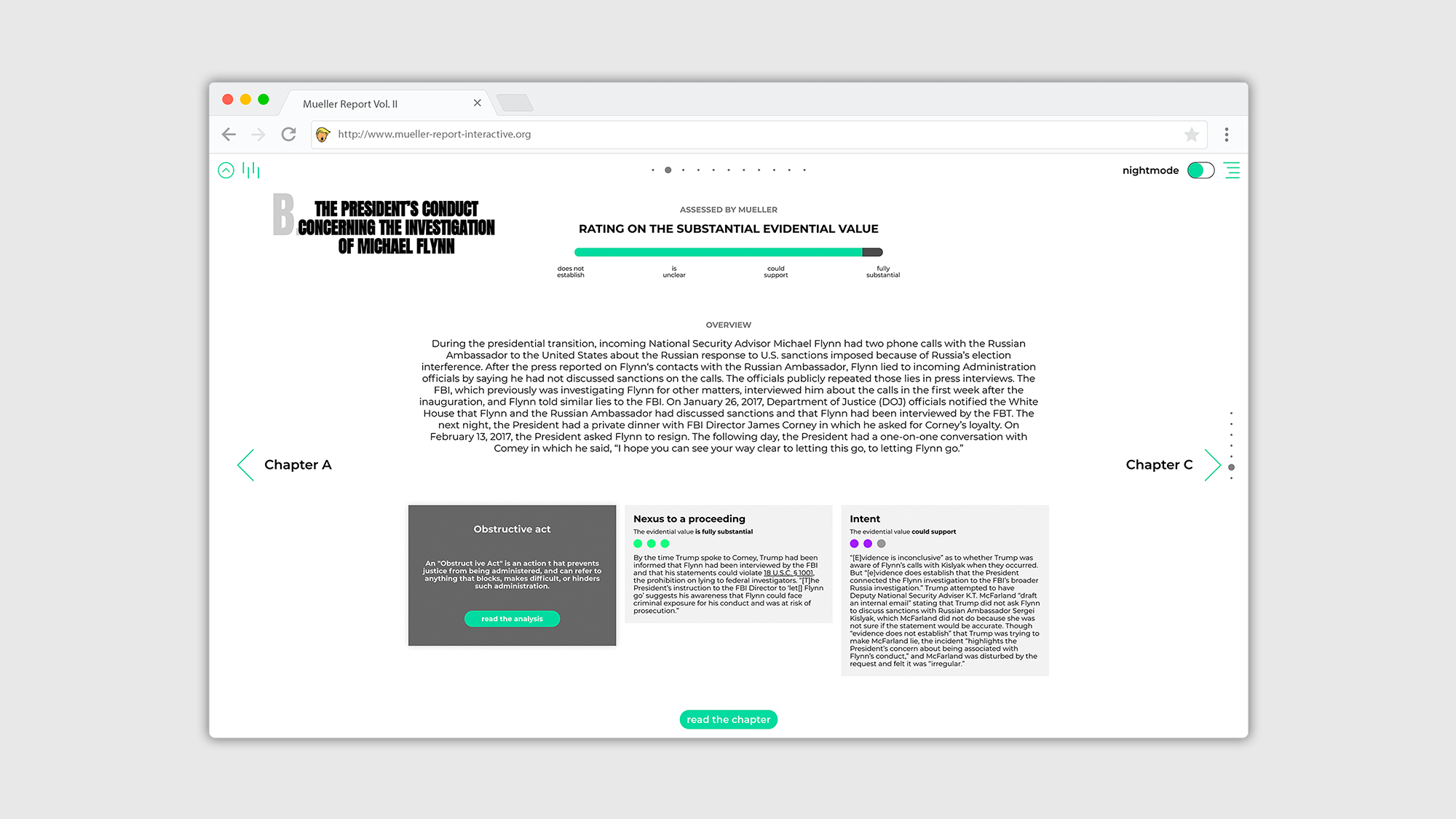
Das Ziel dieser Arbeit ist, den Report mit zeitgenössischen Methoden zu digitalisieren. Dabei liegt der Schwerpunkt auf der Datengenerierung der beinhaltenden Informationen, die parallel zur Digitalisierung des Reports, die Grundlage für eine moderne Visualisierung sowie dynamische Benutzeroberfläche und Navigierung durch die Textinhalte darstellt. Die Intention ist also, durch die Digitalisierung eine individuelle Wiedergabe und interaktive Darstellung zu erzeugen, um das Verständnis ausführlicher und komplexer Themen zu erhöhen und den Report der Öffentlichkeit zugänglicher zu machen.
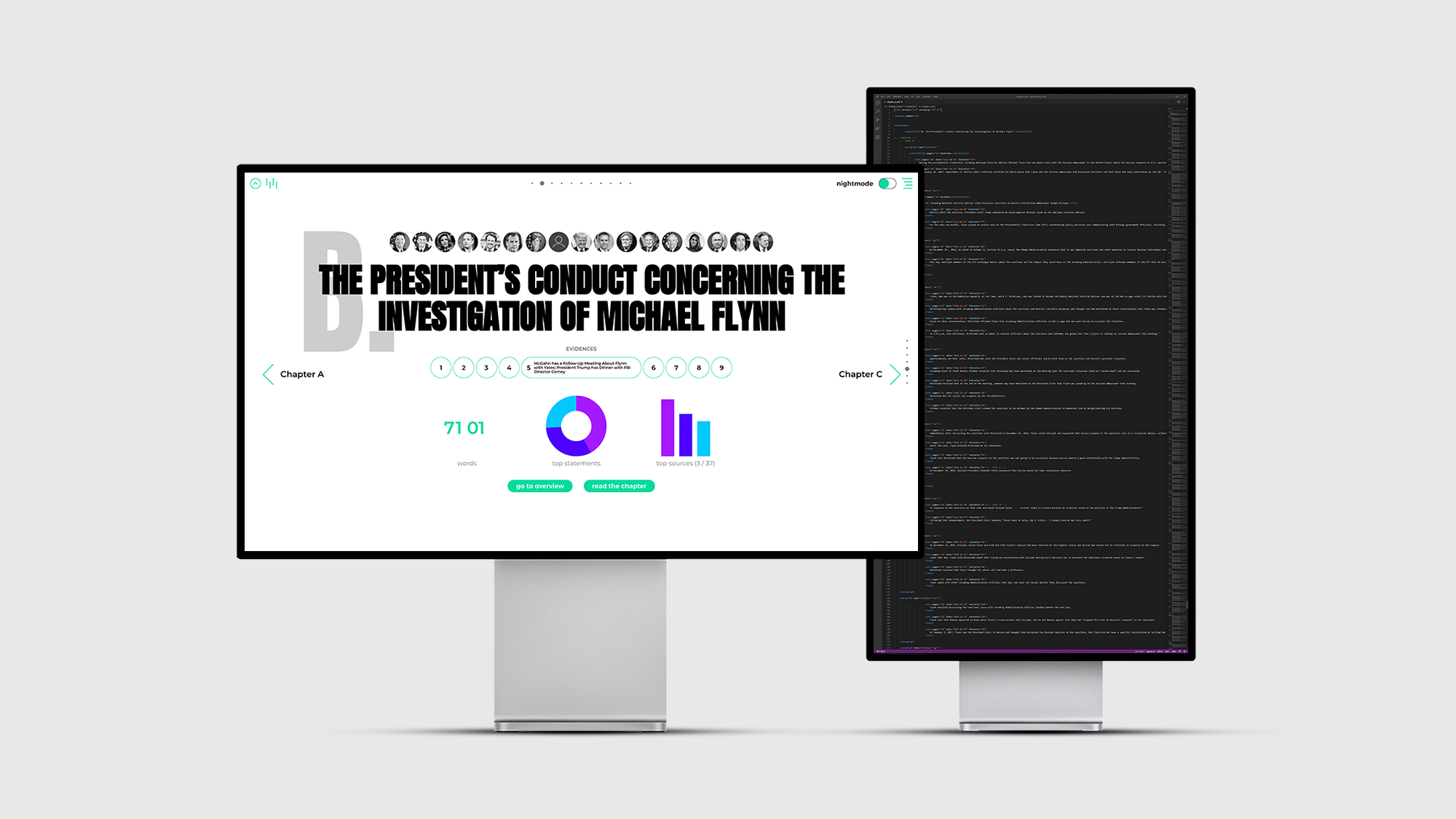
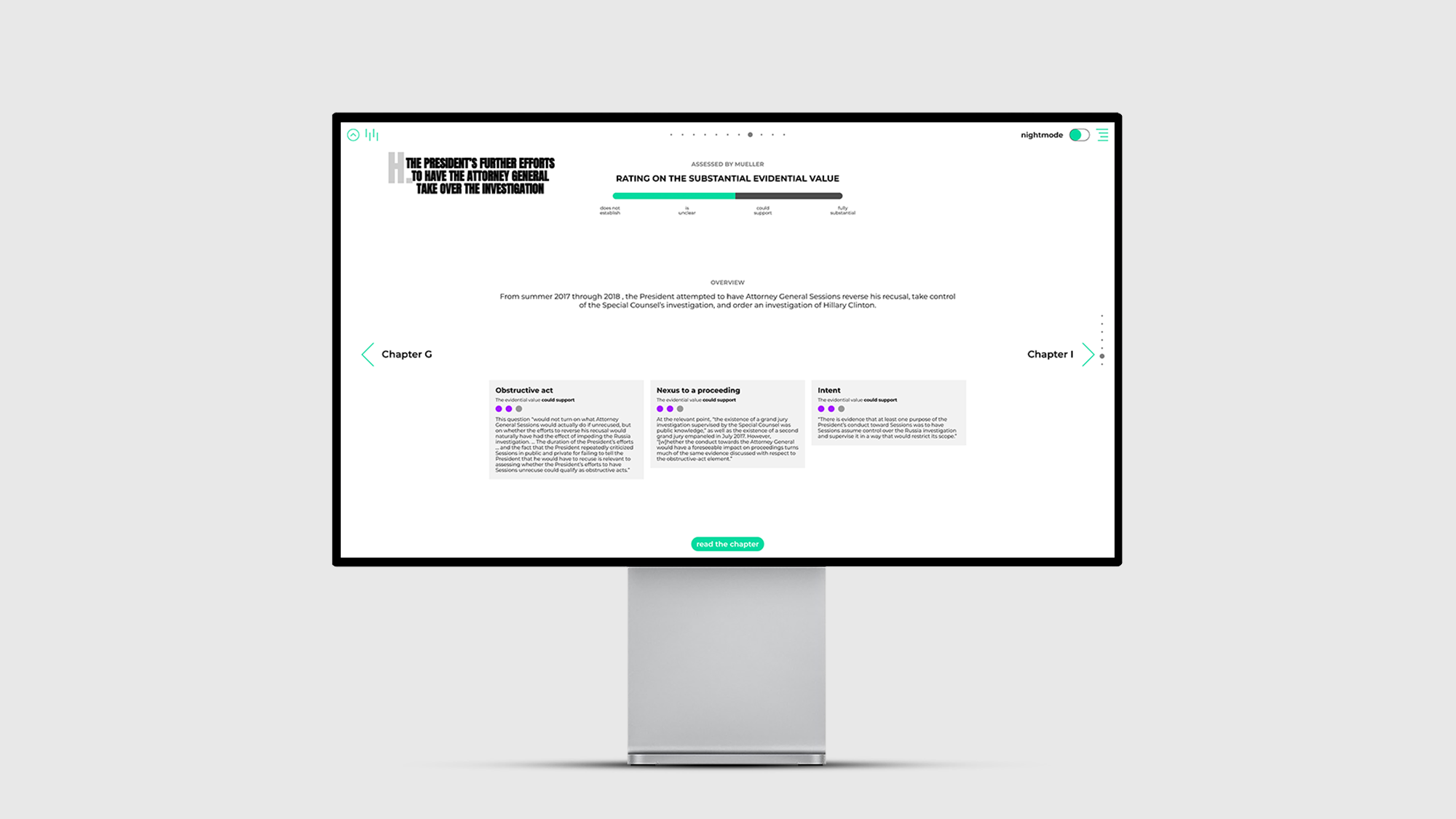
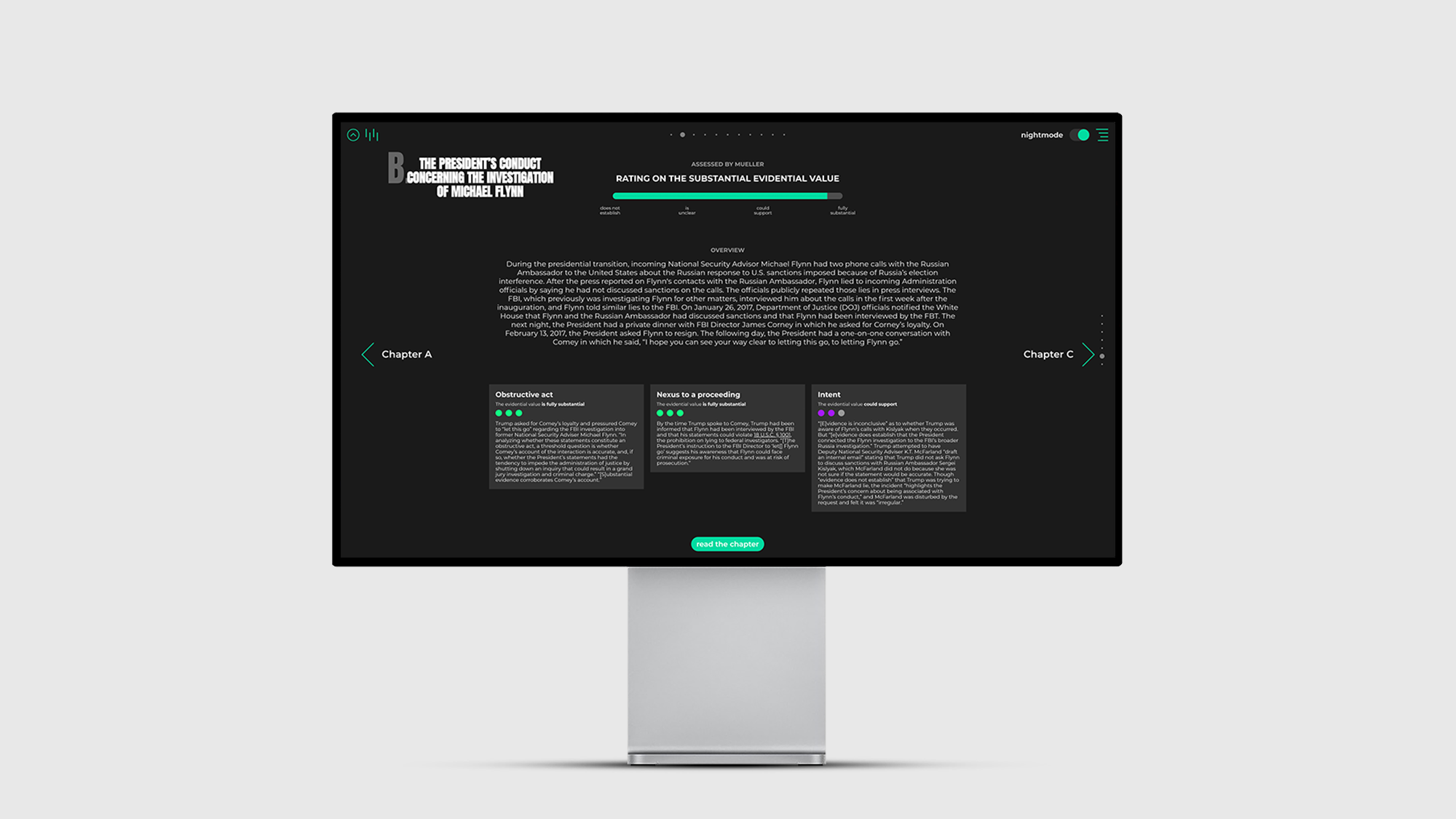
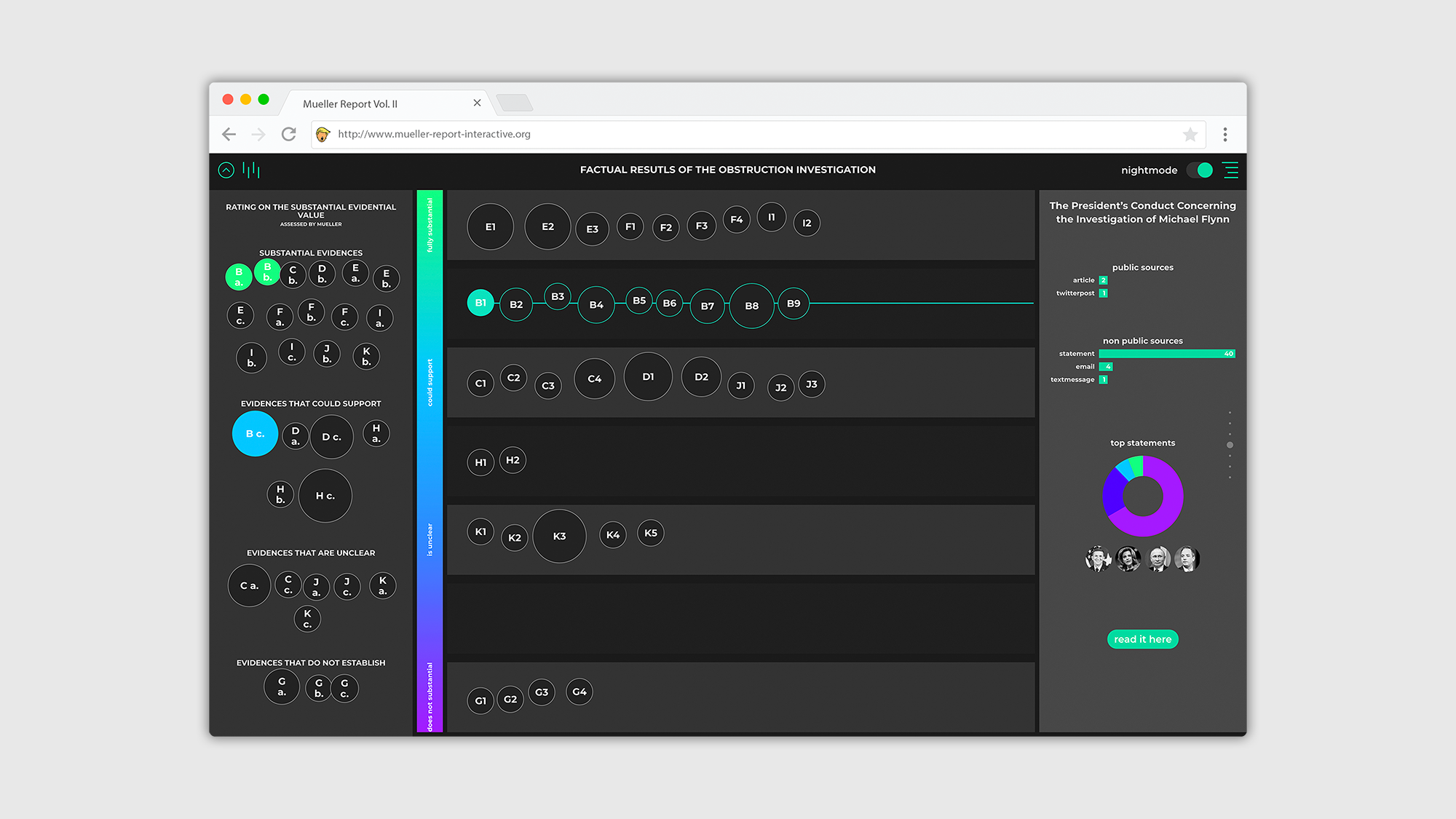
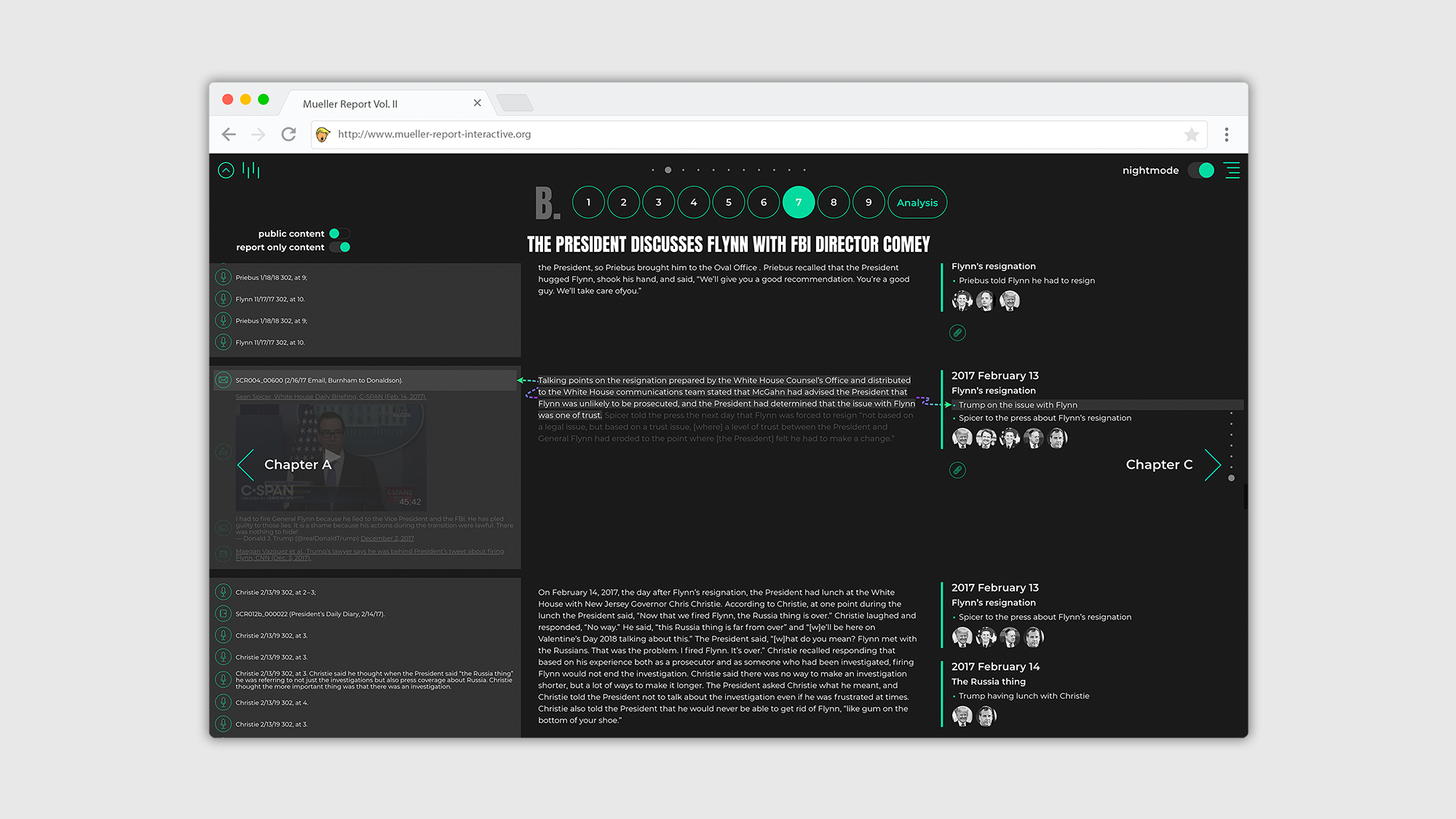
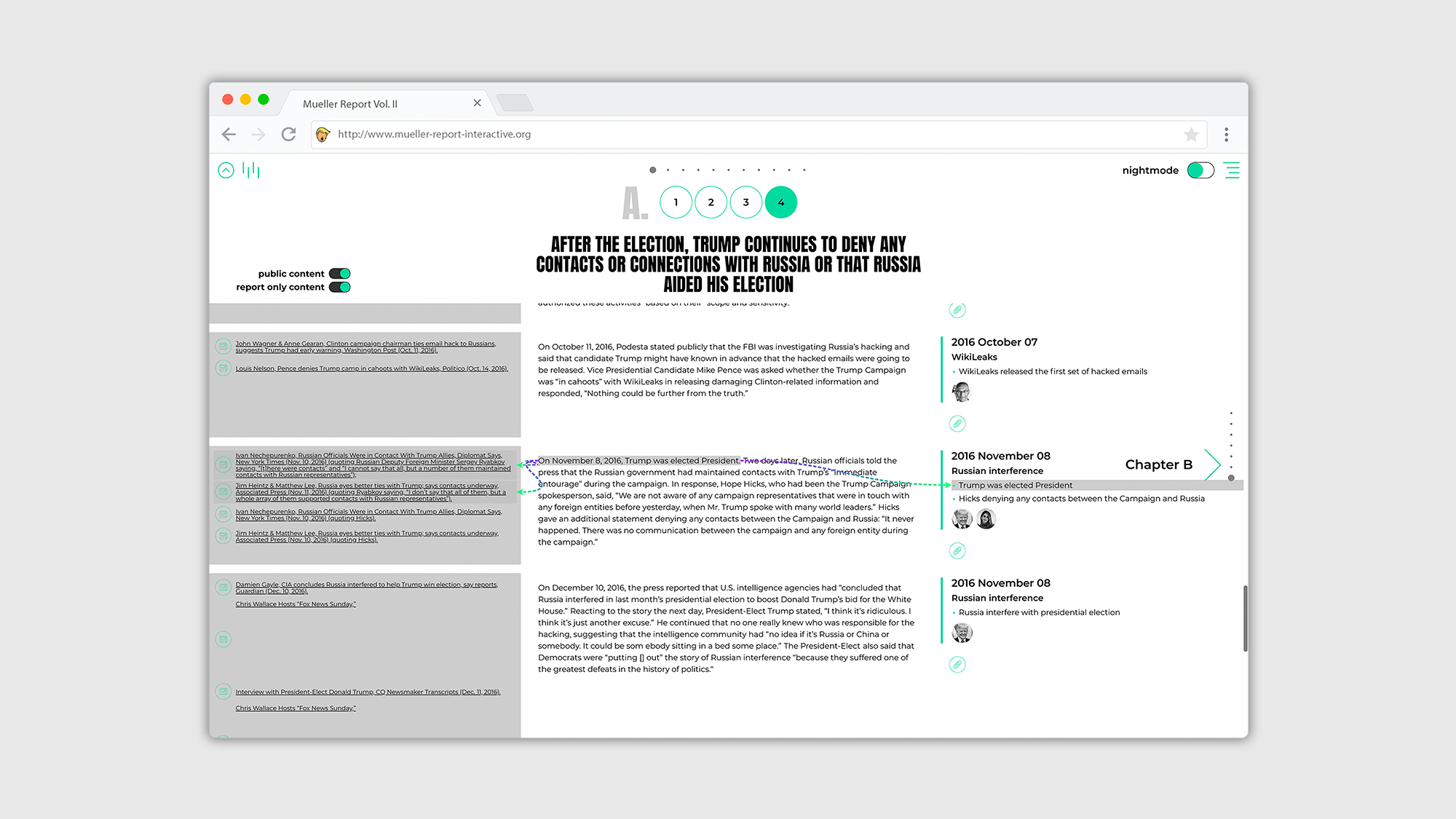
Die Oberfläche wird über den integrierten Webserver der Java Anwendung bereitgestellt und besteht aus einer modernen SPA (single page application), die aus den klassischen Elementen HTML, JavaScript, CSS aufgebaut wurde. Jegliche Textinhalte aus dem Müller Report (Vol. II), stellen in dieser Arbeit die Rohdaten dar. Diese wurden in XML Dateien übersetzt und mit allen verfügbaren Verlinkungen zu bspw. Online-Zeitungsartikeln, Personenprofilen und digitalen Verweisen hinterlegt. Für weitere Ausführungen wurden die geschäftlichen Beziehungen von Personen dokumentiert und Ereignisse, die Ortsangaben beinhalten, wurden mit Koordinaten hinterlegt. Zusätzlich wurden alle Informationen sorgfältig strukturiert und in Kategorien separiert. Unterschiedliche Informationstypen können somit individuell sowie gezielt ausgelesen werden. Dadurch können Informationen auf ihr jeweiliges Aufkommen, die Position im Text sowie auf ihre Quelle untersucht und abgerufen werden. Auf der Oberfläche können sie dadurch interaktiv in Bezug zueinander gesetzt, gefiltert oder einzeln dargestellt werden.
Die Daten aus den XML Dateien werden über die Java Anwendung eingelesen und optimiert, dadurch sind komplexe Sortierungen und Kontextualisierungen der Daten dynamisch und individuell möglich. Ausgelesen werden diese über eine JSON API. Die Anwendung stellt somit primär die Schnittstelle für die Benutzung der aufbereiteten Daten bereit.
Zurück zur Projektübersicht.
Weitere Projekte DESIGN INTERAKTIVER MEDIEN:

Kunstaneignung: Am Nußberger Pfad
Anna Milena Birk

Toolkit Buchbinden
Franziska Györfi

Die Klangtasse
Thore Wiers, Marie Goldbach
